We earn commission when you buy through affiliate links.
This does not influence our reviews or recommendations.Learn more.
It can add custom data, viewing options, and passwords to PDF files.
Importantly, though, PyPDF2 can retrieve text from PDF files.
To installpip, click onget pipto download its installation script.
Install PyPDF2 by executing the following command in the terminal:
2.
To start working with a PDF file you first need to launch the file.
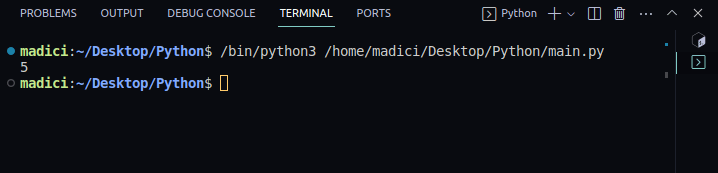
Since our PDF file has 5 pages, we can access each page available in the PDF.
However, counting starts from 0, just like Pythons indexing convention.

Therefore, the first page in the pdf file will be page number 0.
You thus have access to the text on the first page of the PDF file through the variable textPage1.
To use PyMuPDF, you should have Python 3.8 or later.
To get started:
1.
Install PyMuPDF by executing the following line in the terminal:
2.
Import PyMuPDF into your Python file using the following statement:
3.
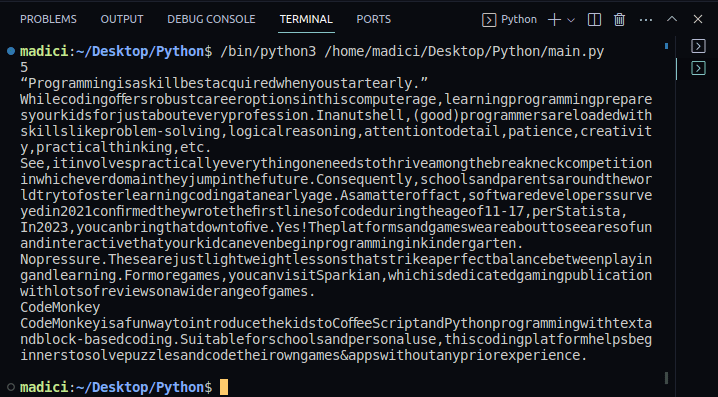
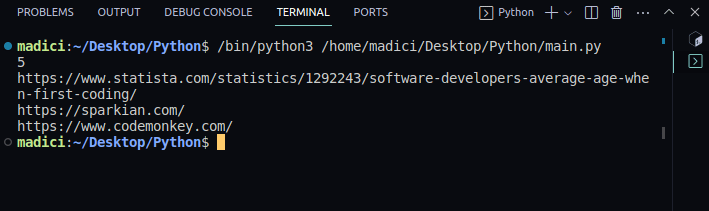
To pull up the PDF you want to extract links from, you first need to open it.
To open it, enter the following line:
4.
The counting of pages starts from zero just like in data structures like arrays and dictionaries.
The entire code that does this is shown below:
8.
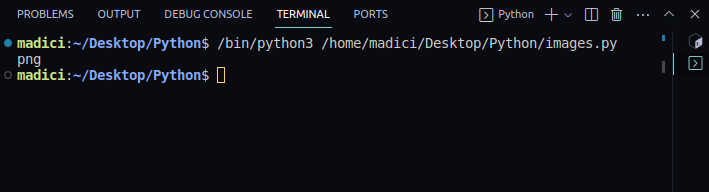
To extract images from a PDF file:
1.
Import PyMuPDF, io, and PIL.
- fire up the PDF file you want to extract images from:
3.
Load the page you want to extract images from:
4.
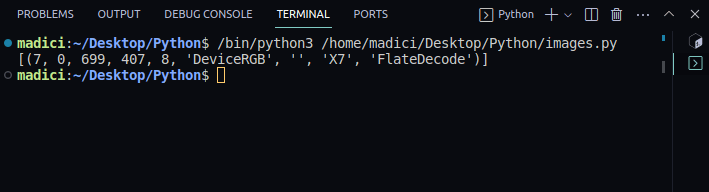
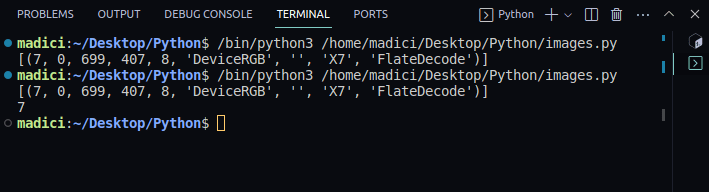
Every image on a PDF file has a unique xref.
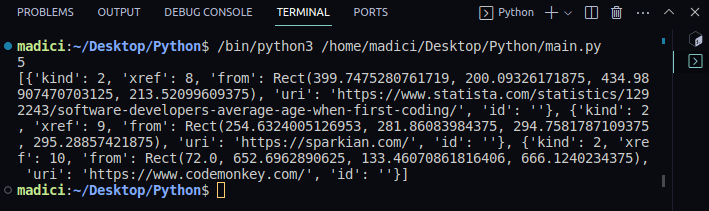
Since we only have one image on the first page, there is only one tuple.
The first element in the tuple represents thexrefof the image on the page.
Therefore, thexrefof the image on the first page is 7.
To extract thexrefvalue for the image from the list of tuples, we use the code below:
6.
From the dictionary returned by theextract_image()function, check the file extension of the extracted image.
The file extension is stored under the key ext:
8.
Extract the image binaries from the dictionary stored inimg_dictionary.
The image binaries are stored under the key image
9.
Create aBytesIOobject and initialize it with the binary image data that represents the image.
Open and parse the image data stored in theBytesIOobject namedimage_iousing the PIL library.
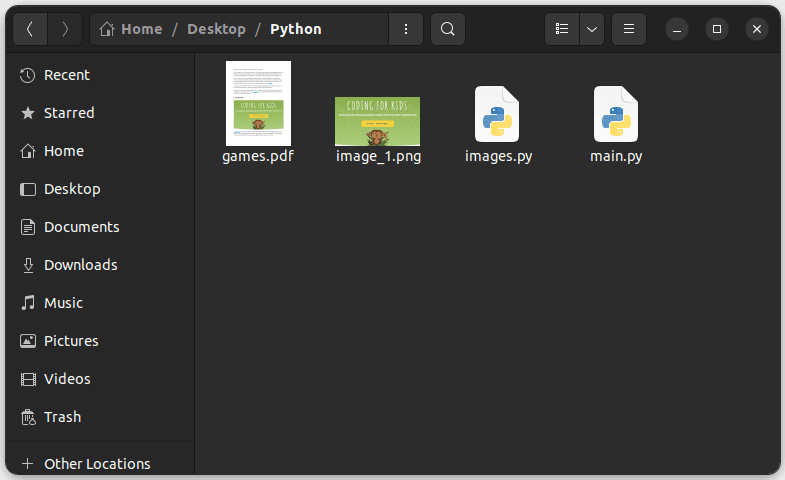
Specify the path where you want to save the image.
The image will be saved as image_1.png.
The PNG extension is important for it to match the original extension of the image.
Save the image and wrap up the ByteIO object.
You may also explore some bestPDF APIsfor every business need.