We earn commission when you buy through affiliate links.
This does not influence our reviews or recommendations.Learn more.
We have discussed the fundamental concepts ofNLP preprocessing and text cleaning.

Before we discuss Vectorization, lets revise what tokenization is and how it differs from vectorization.
What is Tokenization?
Tokenization is the process of breaking down sentences into smaller units called tokens.

Token helps computers to understand and work with text easily.
This article is good
Tokens- [This, article, is, good.]
What is Vectorization?

As we know,machine learning modelsand algorithms understand numerical data.
Vectorization is a process of converting textual or categorical data into numerical vectors.
By converting data into numerical data, you’ve got the option to train your model more accurately.

Why Do We Need Vectorization?
Tokenization and vectorization have different importance in natural language processing (NPL).
Tokenization breaks sentences into small tokens.
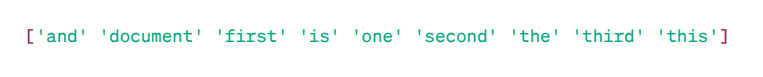
Vectorization converts it into a numerical format so the computer/ML model can understand it.
Vectorization is not only useful for converting it to numerical form but also useful in capturing semantic meaning.
Vectorization can reduce the dimensionality of the data and make it more efficient.
This could be very useful while working on a large dataset.
Many machine learning algorithms require numerical input, such as neural networks, so that vectorization can help us.
There are different types of vectorization techniques, which we will understand through this article.
The bag of words approach can be useful in text classification, sentiment analysis, and document retrieval.
Suppose, you are working on lots of text.
These vectors consist of non-negative numbers (0,1,2…..) that represent the number of frequencies in that document.

The bag of words involves three steps:
Step 1:Tokenization
It will break documents into tokens.
Convert to a dense array
In this step, we will convert our representations into dense array.
Also, we will get feature names or words.
We have four sample text documents, and we have identified nine unique words from these documents.
We stored these unique words in our vocabulary by assigning them Feature Names.
Then, our Bag of Words model checks if the first unique word is present in our first document.
If it is present, it assigns a value of 1 otherwise, it assigns 0.
If the word appears multiple times (e.g., 2 times), it assigns a value accordingly.
If we want a single word as a feature in the vocabulary key Unigram representation.

n grams = Unigrams, bigrams…….etc.
There are many libraries like scikit-learn to implement bag of words: Keras, Gensim, and others.
This is simple and can be useful in different cases.
But, Bag of words is faster but it has some limitations.
To solve this problem we can choose better approaches, one of them is TF-IDF.
Lets, Understand in detail.
TF- IDF gives importance to words in a document by considering both frequency and uniqueness.
Words that get repeated too often dont overpower less frequent and more important words.
TF: Term Frequency measures how important a word is in a single sentence.

IDF: Inverse document frequency measures how important a word is in the entire collection of documents.
These words can be useful in finding the main theme of the document.
First, we will create a vocabulary of unique words.
Lets find TF and IDF for these words.
TF:
Now, Lets calculate the IDF.
TF-IDF is mostly used in text classification, building chatbot information retrieval, and text summarization.

Create TF-IDF Matrix
Lets, train our model by providing text.
After that, we will convert the representative matrix to dense array.
Also, you’re able to combine words in groups of 2,3,4, and so on using n-grams.
There are other parameters that we can include: min_df, max_feature, subliner_tf, etc.
Until now, we have explored basic frequency-based techniques.
But, TF-IDF cannot providesemantic meaning and contextual understandingof text.
This was developed byTomas Mikolovand his team at Google in 2013.
Word2vec represents words as continuous vectors in a multi-dimensional space.
Word2vec aims to represent words in a way that captures theirsemantic meaning.
Word vectors generated by word2vec are positioned in a continuous vector space.
Ex Cat and Dog vectors would be closer than vectors of cat and girl.
Two model architectures can be used by word2vec to create word embedding.
Skip-gram:It is a word embedding model, but it works differently.
Instead of predicting the target word, skip-gram predicts the context words given target words.
Skip-grams is better at capturing the semantic relationships between words.
We will be going through a pre-trained model.
After that, we will tokenize our sentences usingword_tokenize.
Lets train our model:
We will train our model by providing tokenized sentences.
The similarity score indicates how closely related two words are in the vector space.
Ex
Here, word helps with cosine similarity-0.005911458611011982with word avengers.
The negative value suggests that they might dissimilar with each other.
Its a really cool tool for seeing CBOW and skip-gram in action.
Similar to Word2Vec, we have GloVe.
GloVe can produce embeddings that require less memory compared to Word2Vec.
Lets, understand more about GloVe.
GloVe
Global vectors for word representation (GloVe) is a technique like word2vec.
It is used to represent words as vectors in continuous space.
Word2vec is a window-based method, and it uses nearby words to understand words.
Whereas GloVe captures both global and local statistics to come with word embedding.
Use GloVe when you want word embedding that captures broader semantic relationships and global word association.
GloVe is better than other models on named entity recognition tasks, word analogy, and word similarity.
Positive values indicate positive associations with certain concepts, while negative values indicate negative associations with other concepts.
Values can be different for different models.
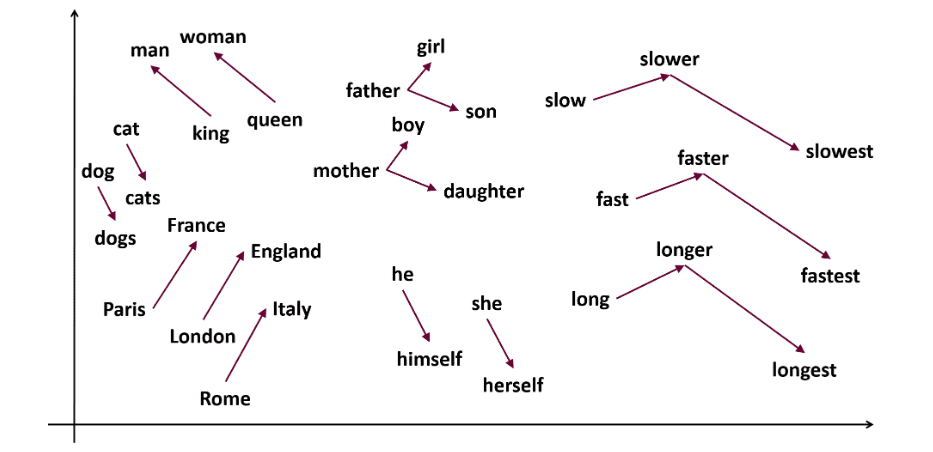
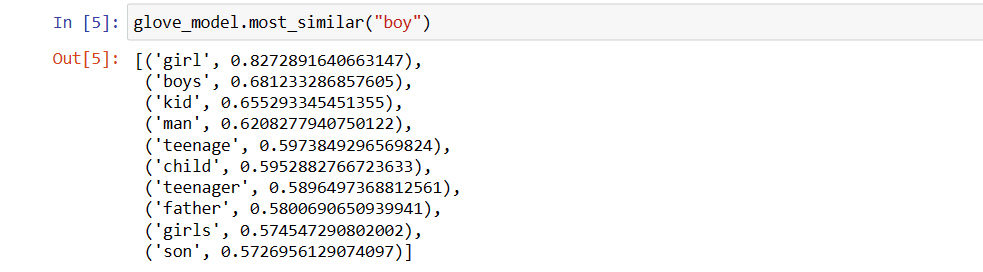
Now, we will venture to find How accurately the model will get semantic meaning from the provided words.
Our model is able to find perfect relationship between words.
Define the list of words you want to visualize.
Create embedding matrix:
Lets, write code for creating embedding matrix.
Define a function for t-SNE visualization:
From this code, we will define function for our visualization plot.
Whereascow, dog, and catare similar to each other because they are animals.
So, our model can find semantic meaning and relationships between words also!
you’re able to use this embedding matrix however you like.
It can be applied to word similarity tasks alone or fed into a neural networks embedding layer.
GloVe trains on a co-occurrence matrix to derive semantical meaning.
This is how GloVe accomplishes adding global statistics to the final product.
And thats GloVe; Another popular method for vectorization is FastText.
Lets discuss more about it.
FastText
FastText is an open-source library introduced byFacebooks AI Research teamfor text classification and sentiment analysis.
FastText provides tools for training word embedding, which are dense vector represent words.
This is useful for capturing the semantic meaning of the document.
FastText supports both multi-label and multi-class classification.
As we discussed, other models, like Word2Vec and GloVe, use words for word embedding.
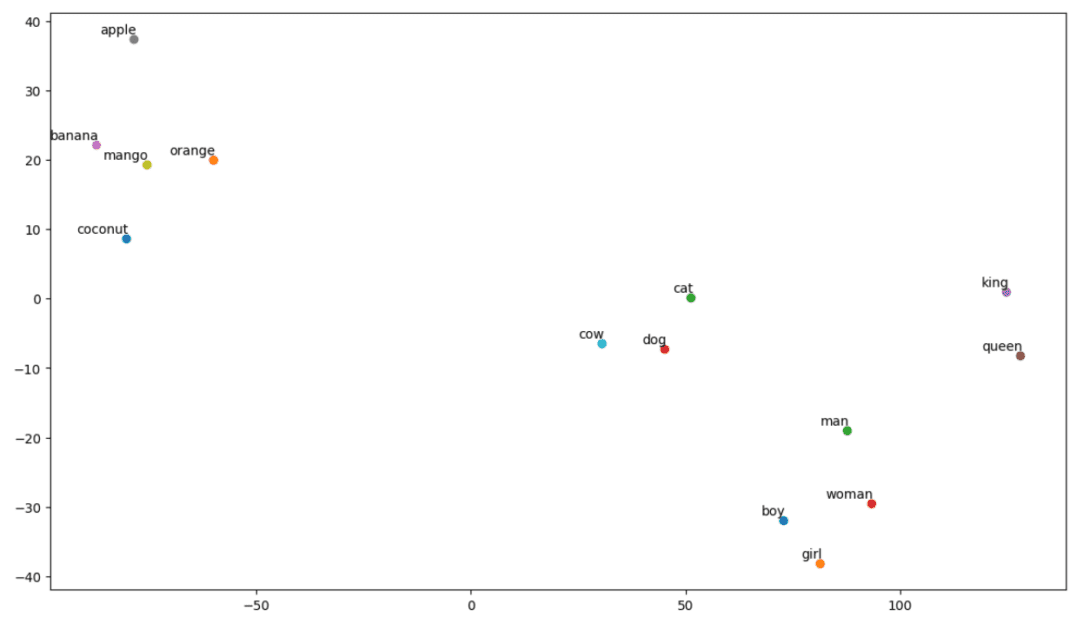
But, the building block of FastText is letters instead of words.
Which means they use letters for word embedding.
Using characters instead of words has another advantage.
Less data is needed for training.
As a word becomes its context, resulting in more information can be extracted from the text.
Word Embedding obtained via FastText is a combination of lower-level embeddings.
Now, lets look at how FastText utilizes sub-word information.
Lets say we have the word reading.
We are going to use a pre-trained model.
First, you gotta install FastText.
Like with the kind of drugs with which theyre associated.
We omitted a lot of preprocessing in this step.
Otherwise, our article will be too large.
In real-world problems, its best to do preprocessing to make data fit for modeling.
Now, write prepared data points to a .txt file.
Lets train our model.
We will get Predictions from our model.
The model predicts the label and assigns a confidence score to it.
The choice of technique depends on the task, data, and resources.
We will discuss the complexities of NLP more deeply as this series progresses.
Next, check out the best NLP courses to learn Natural Language Processing.
