We earn commission when you buy through affiliate links.
This does not influence our reviews or recommendations.Learn more.
Speech synthesis helps these devices generate these AI voices.

What is Speech Synthesis?
Supervised learning is often employed, where AI voice models are trained using large datasets of human speech.
These datasets serve as a treasure trove of linguistic patterns, phonetic structures, and speech dynamics.

This method captures intricate details like rhythm and tone, making AI voices sound exceptionally natural and expressive.
Neural TTS represents a significant advancement, bringing AI voices closer to the nuanced qualities of human speech.
Now, Lets understand all the steps involved in speech synthesis in brief.

Speech Synthesis Process
The process begins with analyzing the input text.
Linguistic rules and models are applied to determine pronunciation, stress patterns, and intonation.
This step involves ensuring that the synthesized speech sounds natural and coherent.
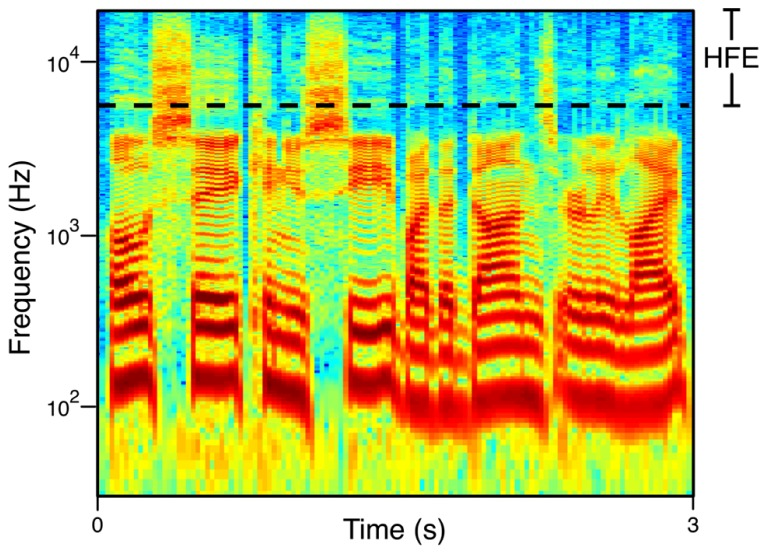
Acoustic models are used to represent the sound characteristics of speech.
Traditional methods involved defining the resonance frequencies of the vocal tract (formant synthesis).
Modern approaches use statistical parametric synthesis or deep learning to model complex relationships between text and speech features.
AI voice models are trained on extensive datasets of recorded human speech.
Deep learning, specifically neural networks, is a key technology in modern AI voice synthesis.
Waveform synthesis is the process of turning the information from the spectrogram into the actual speech signal.
Techniques like WaveNet generate high-quality, natural-sounding waveforms.
After synthesis, post-processing techniques may be applied to refine the output.
This can involve adjusting pitch and duration or adding effects to enhance naturalness.

The final output is AI-generated speech that corresponds to the input text.
Some models employ transfer learning, where pre-trained models are fine-tuned for specific voices or languages.
This helps in achieving more personalized and context-aware voices.
Speech Synthesis systems often undergo continual improvement through feedback loops.
User interactions, corrections, and preferences contribute to refining the models over time.
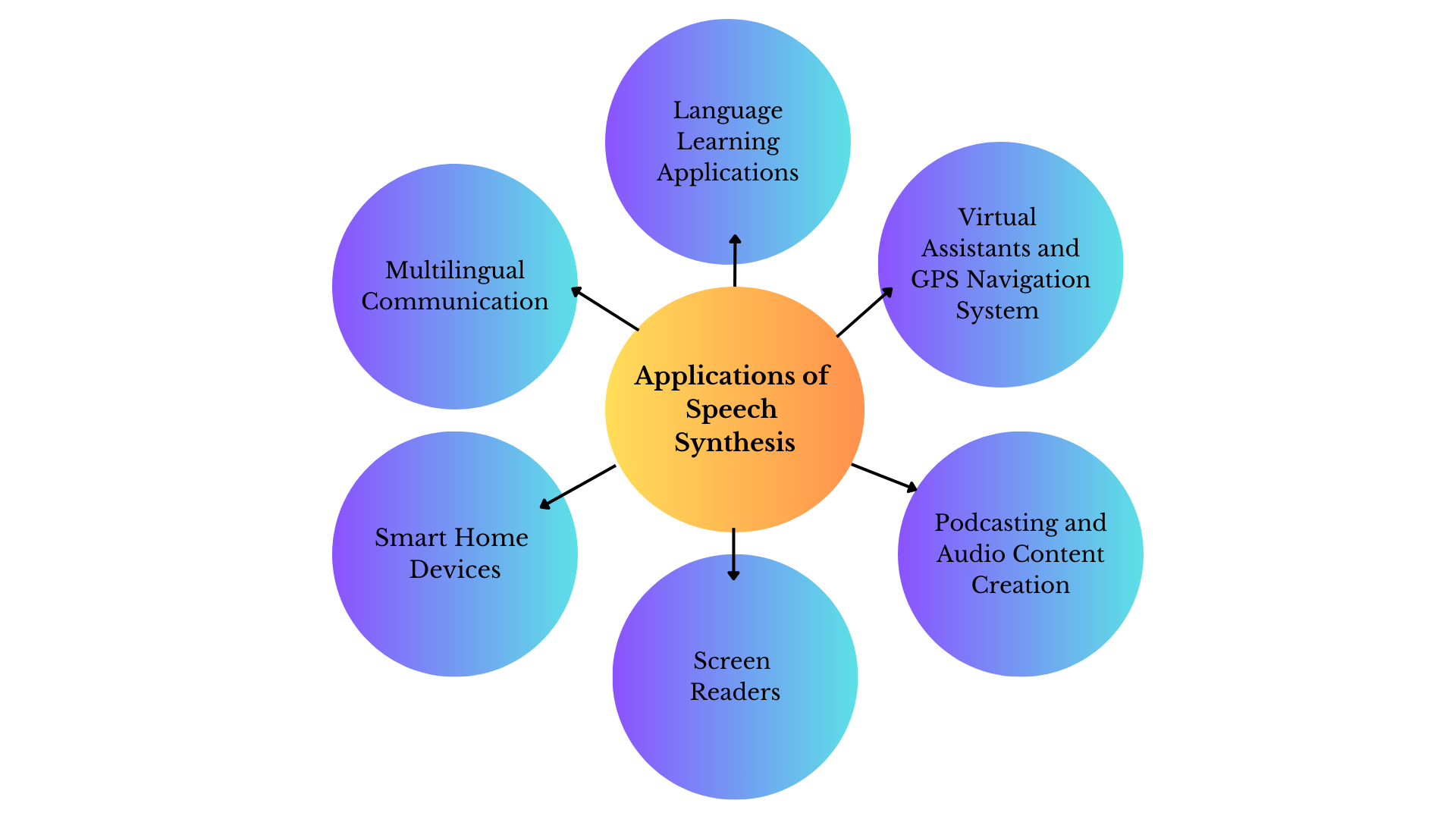
Real-Life Applications of Speech Synthesis
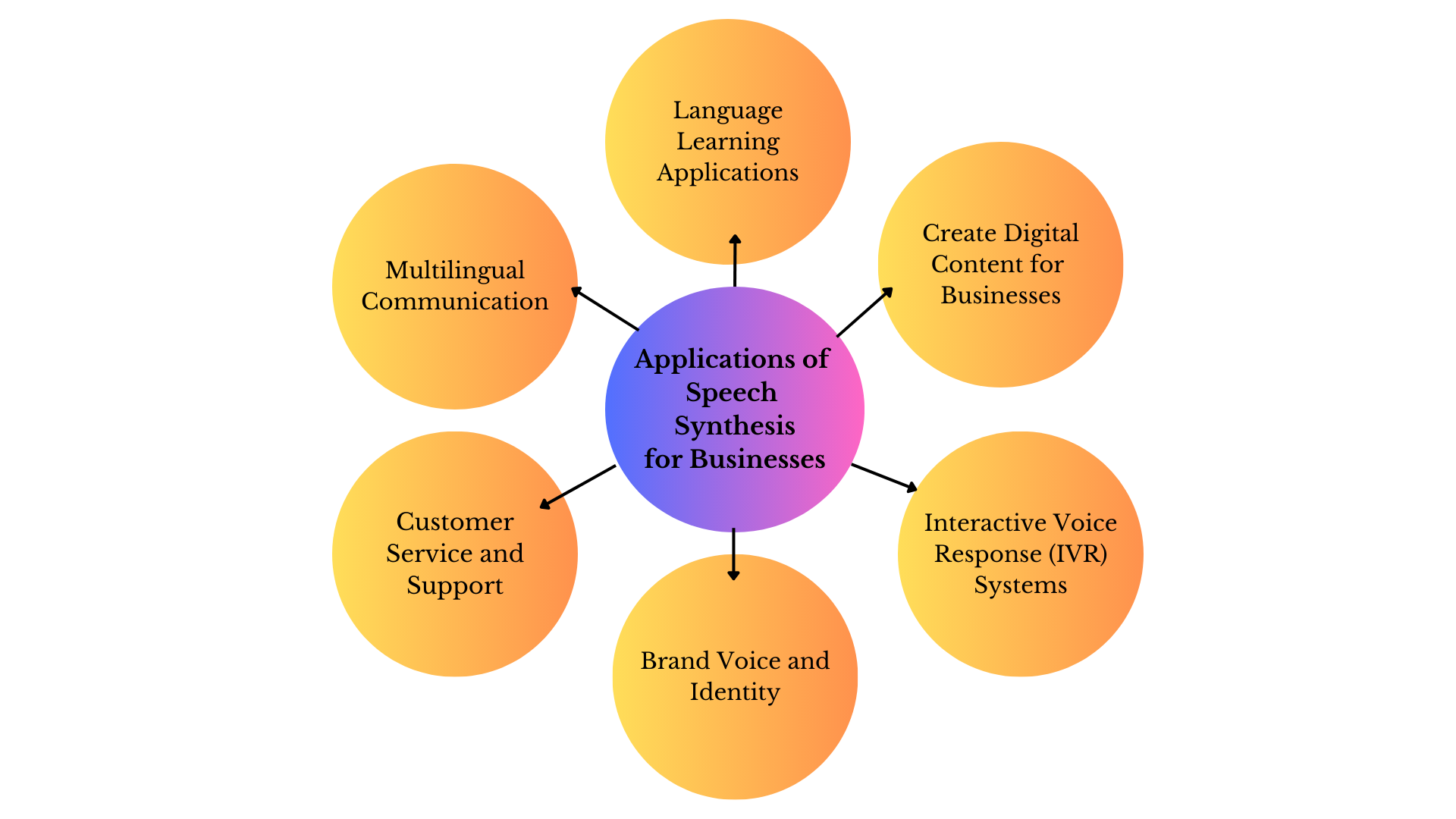
Moreover, it is beneficial for many businesses.
